
An RNN that learns to talk like you
I would like to share a personal project I am working on, that uses sequence-to-sequence models to reply to messages in a similar way to how I would do it (i.e. a personalized chatbot) by using my personal chat data that I have collected since 2014. If you would like to learn more about this type of model, have a look at this paper. I am working on two versions, one at the character level and one at the word level. The full notebooks with code can be found here: char-level, word-level.
Usually, a sequence-to-sequence model is used for translation tasks. The encoder reads an input in a specific source language, and passes the encoded inner state to the decoder, which then produces text in the target language. I was curious if I could apply this model to message generation. I try to encode an input message and then produce an answer / reply by using the decoder.
I will show important parts of the code here, but if you get lost or don’t know where a variable comes from, please check the notebook.
Word level vs character level
Each one has benefits and drawbacks, and I am studying which one would work best for this task.
Word level allows to increase the amount of information you can put into a sequence. Since each word is one token, you can put up to seq_length words into a sequence, as opposed to only seq_length characters if you are working at character level. It also allows the model to work at a higher level of abstraction. One drawback is that we are ‘accidentally’ generating tokens for all misspelled words in the dataset (I have tons of them), as well as all variarions of similar words. For example, me and my friends frequently use ‘xD’, which can also be ‘xDD’ or ‘xDDD’. Cleaning this is a very difficult task.
If you work at character level, you are considerably reducing the vocabulary size. While I have more than 15.000 different words in my dataset, I have only 290 different characters in use (including emojis! ![]() ). Since we need to one-hot encode our tokens (except if we use embeddings, which I will mention later), this helps to drastically reduce memory usage. Missspelled words are automatically taken care of in this case since they are much less frequent than the correctly spelled versions. The model will thus learn to spell them correctly.
). Since we need to one-hot encode our tokens (except if we use embeddings, which I will mention later), this helps to drastically reduce memory usage. Missspelled words are automatically taken care of in this case since they are much less frequent than the correctly spelled versions. The model will thus learn to spell them correctly.
I will follow the word level code, but feel free to look at the notebook for the character level code to see the differences.
The correlation assumption
In order to teach the neural network about how someone usually talks, an assuption needs to be made regarding correlation of the data you feed it. It is assumed that previous messages are related to how you replied. Although this is normally the case, a number of problematic exceptions need to be taken into account:
-
Someone could be replying to a topic of a previous conversation. In this situation, the immediately previous message is not related and breaks our assumption.
-
Someone could be introducing a new topic, starting a new “chain” of relationships. Of course, this first message is then only related to succedding messages, and not to the previous ones.
-
We sometimes reply to very old messages or reply to several things in a row, having two parallel chains.
Here, I decided to ignore these edge cases and hold the assumption.
Preparing the dataset
The chatbot notebook I provided expects a json file, which should contain a list of already separated tokens. So let’s preprocess the data and obtain this json. These preprocessing steps can also be found in my data preprocessing notebook.
First we import the things we need and define some helper functions to load and save files.
import regex as re
import numpy as np
import matplotlib.pyplot as plt
from google.colab import drive
drive.mount('/content/gdrive')
import json
def load_doc(filename):
# open the file as read only
file = open(filename, 'r', encoding='utf-8')
# read all text
text = file.read()
# close the file
file.close()
return text
# save tokens to file, one dialog per line
def save_doc(lines, filename):
j = json.dumps(lines)
file = open(filename, 'w')
file.write(j)
file.close()
While using Google Colab, you can access your drive contents by using google.colab.drive. Here I am loading a text file I have stored in mine, so please replace this with your own chat dataset.
text = load_doc('/content/gdrive/My Drive/Projects/datasets/whatsapp_dataset/conversation.txt').lower()
I am working with text that looks like this:
11/16/14, 09:54 - raul: Te tendre que hacer una lista de capítulos no?
11/16/14, 10:01 - mario: De los sueltos?
11/16/14, 10:07 - raul: Si
11/16/14, 10:07 - raul: Hay 12 de la trama principal
So lets create a list of lines and clean it up a bit:
# Split into messages and remove date header
lines = re.split(r'\d+\/\d+\/\d+,\s\d+:\d+\s-\s', text)
lines = lines[1:]
# Replace multiple newlines by just one newline
lines = [re.sub("(\\n)+", '\n', line) for line in lines]
# Delete trailing newlines
lines = [re.sub("\n$", '', line) for line in lines]
You can check your max and average message length, if you are curious.
# Whats the maximum message length?
np.max([len(line) for line in lines])
# And the average message length?
np.mean([len(line) for line in lines])
Now we can separate our data into tokens. The first token of each line is going to be the person to whom the message belongs to. Any non alphanumeric character is considered a unique token (punctuation, emojis, etc). Note that [\p{L}] matches any codepoint of the category ‘letter’. As opposed to [a-z], it will also match non-english characters like letters with accents or completely different alphabets like Japanese (おはよう!). Only consecutive ‘letters’ are grouped together into one word. Something like good-looking will be separated into three tokens. This gives the model some flexibility by giving it smaller building blocks.
# We gotta separate the text into tokens.
# By convention, the first element of each sequence is the name of the person saying it
splitted_lines = []
for i,line in enumerate(lines):
match = re.match('([a-z]+):', line)
# Ignore messages without name tag
if not match: continue
name = match.group(1)
line = re.sub('^[a-z]+: ', '', line)
splitted_line = re.findall('(?:[\p{L}]+)|\S', line, re.UNICODE)
splitted_lines.append([name, *splitted_line])
Now comes a challenging part. How do we deal with consecutive messages from the same person? There are many ways in which one could solve this. Since I want to teach the model how I reply to a message given an input, I have to group all my messages into one, and consider it a reply. To keep the idea of separation between these now grouped messages, I will add newlines (\n) between them. The neural network will then also learn to put newlines into his responses, and we can manually separate this response into several messages again afterwards.
Onother more sophisticated way could be to separate it into blocks of close in time messages (put messages together that are sent shortly after one another, and separate into a different block those who are more distant, since they could be unrelated). However, these and other methods need to solve a more complex correlation assumption. Your reply will most likely be correlated to all and not just the last message of your partner. Also, your next messages will also likely be correlated to both your previous message and your partners messages. I am open to suggestions on how one could model this correctly.
# Join all consecutive messages from the same person into one big message.
grouped_lines = []
name = splitted_lines[0][0]
grouped_lines.append(splitted_lines[0])
for i in range(1, len(splitted_lines)):
if splitted_lines[i][0] == name:
grouped_lines[-1].append('\n')
grouped_lines[-1].extend(splitted_lines[i][1:])
else:
name = splitted_lines[i][0]
grouped_lines.append(splitted_lines[i])
Finally I separate them into two, one for inputs and one for outputs, and I save the result as json.
# Here i'm splitting the lines into input that I receive and reply that I give
mario_response = [line[1:] for line in grouped_lines if line[0] == 'mario']
mario_input = [grouped_lines[i-1][1:] for i in
range(len(grouped_lines)) if grouped_lines[i][0] == 'mario']
save_doc(mario_input, '/content/gdrive/My Drive/Projects/datasets/whatsapp_dataset/mario_input.txt')
save_doc(mario_response, '/content/gdrive/My Drive/Projects/datasets/whatsapp_dataset/mario_response.txt')
Chatbot phase 1: getting ready
Now comes the code regarding the chatbot per-se. Lets load the necessary stuff, define hyperparameters and have a peek at out data.
# Import necessary packages
import regex as re
import numpy as np
import matplotlib.pyplot as plt
from google.colab import drive
import keras
from keras.models import Model
from keras.layers import Input, CuDNNLSTM, Dense, Embedding
import itertools
import json
# A helper function to load a file as utf-8 text
def load_doc(filename):
file = open(filename, 'r', encoding='utf-8')
text = file.read()
file.close()
return text
# Our hyperparameters, can be tuned at liking
batch_size = 64
latent_dim = 256
seq_length = 50
num_lines = 1000 # this is per person, so total is double
drive.mount('/content/gdrive')
input_messages = json.loads(load_doc('/content/gdrive/My Drive/Projects/datasets/whatsapp_dataset/mario_input.txt'))
response_messages = json.loads(load_doc('/content/gdrive/My Drive/Projects/datasets/whatsapp_dataset/mario_response.txt'))
# Check that your data is looking good
print(*input_messages[:3], sep='\n')
print(*response_messages[:3], sep='\n')
It is possible to use generators to solve this issue, but for now we will one-hot encode all our target sequences (more on this later). For this reason, the amount of lines you can work with may be limited by the memory available. Cut your lines accordingly.
# Cut your dataset to include only num_lines lines.
input_messages = input_messages[:num_lines]
response_messages = response_messages[:num_lines]
This neural network needs an upper bound for the length of a message. All messages with length above should be cut accordingly. You can study how long your average message is by running the code below. Although here we take the first seq_length words, some more sophisticaded way to trim the messages could be used. For example, try to use the last seq_length messages for the input. They might have more correlation to your reply than the beginning.
# Check how long your messages are
max = 0
mean = 0
count = 0
for line in input_messages + response_messages:
mean += len(line)
if len(line) > seq_length:
count += 1
if max < len(line):
max = len(line)
mean /= len(input_messages + response_messages)
print(f"Your longest message is {max} words long. The mean is {mean}.")
print(f"By using a seq_length of {seq_length}, you are cutting {count*100/(num_lines*2)}% of your messages.")
Trim your lines once you decided the length. Since we will append either a START or an END token to our response lines, we need to make sure we leave space for that. Note how any lines below seq_length will be ignored with this indexing expression. The reason why we need these extra tokens is because we will use a technique called teacher forcing.
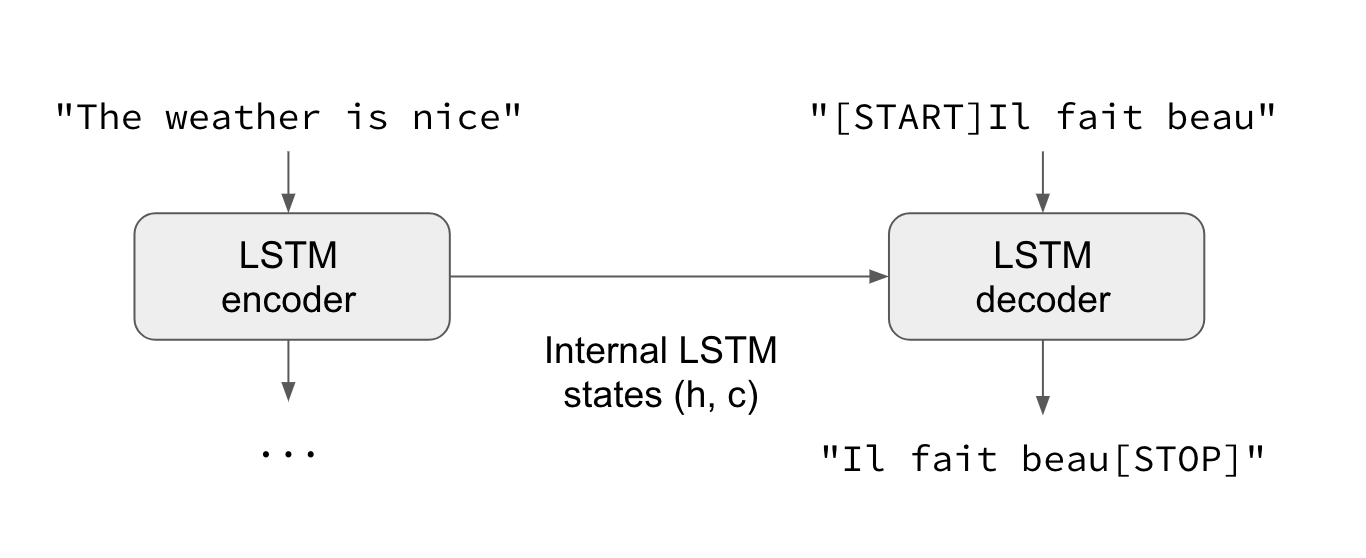 Source: https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html
Source: https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html
The decoder will get as input the target we want to generate, including one START token at the beginning. Given this, it must learn to generate the actual first character. Once it did that, we feed it that first character as input and let it generate the second one, etc. Finally, it must learn how to stop by producing the STOP token.
# Trim inputs to seq_length and responses to seq_length - 1
# This way we make space for START or END tokens
for i in range(num_lines):
input_messages[i] = input_messages[i][:seq_length]
for i in range(num_lines):
response_messages[i] = response_messages[i][:seq_length - 1]
# We'll use '\t' as START and '\r' as END token, since \n could be part of the message
for i in range(len(response_messages)):
# Add starting '\t'
response_messages[i].insert(0, '\t')
# Trim trim out two more characters (to make space for the new tokens) and add \r
response_messages[i].append('\r')
Chatbot phase 2: Tokenization
A neural network needs numbers to run, so we need to turn our characters into numbers. Each unique character (even emojis!) will receive a unique number. Since not all lines have seq_length length, we need to fill them in order to obtain a numpy array. This filler will be \v (any other random character is also okay, as long as it’s not already in your dataset).
# Create translation dictionaries
# I will use \v as a filler for lines with less than seq_length words, it will get index 0.
# It was chosen at random, we just need something that is not part of our normal vocabulary.
words = list('\v')
for line in (input_messages + response_messages):
for word in line:
if not word in words:
words.append(word)
word_to_ix = dict((c, i) for i, c in enumerate(words))
ix_to_word = dict((i, c) for i, c in enumerate(words))
vocab_size = len(word_to_ix)
Now we can transform our lines into numpy matrices by using these dictionaries.
# Input of encoder is input lines
encoder_input_data = [[word_to_ix[word] for word in line]
for line in input_messages]
encoder_input_data = np.array(list(
itertools.zip_longest(*encoder_input_data, fillvalue=0)), dtype=np.int16).T
# Input of decoder is response lines without END token ('\r').
decoder_input_data = [[word_to_ix[word] for word in line[:-1]]
for line in response_messages]
decoder_input_data = np.array(list(
itertools.zip_longest(*decoder_input_data, fillvalue=0)), dtype=np.int16).T
# Output of decoder is response lines without START token ('\t').
decoder_target_data = [[word_to_ix[word] for word in line[1:]]
for line in response_messages]
decoder_target_data = np.array(list(
itertools.zip_longest(*decoder_target_data, fillvalue=0)), dtype=np.int16).T
# Only target sequences need to be one-hot encoded, since we are using an embedding
decoder_target_data = keras.utils.to_categorical(decoder_target_data,
num_classes=vocab_size)
# Sanity check: shapes are looking good.
print("Your data looks like this:")
print(f"encoder_input_data shape: {encoder_input_data.shape}")
print(f"decoder_input_data shape: {decoder_input_data.shape}")
print(f"decoder_target_data shape: {decoder_target_data_h.shape}")
Chatbot phase 3: training
Finally, we can define our model. We will use an embedding because our vocabulary size is very big. This is the reason why we did not need to create one-hot encodings of our data, except for the targets. This embedding will transform our integer values into a vector of latent_dim entries, which should be capable of representing all our different words. Similar words (and thus also typos and similar expressions) will have similar vectors, thus aiding us to clean them out a little bit.
#Encoder
encoder_inputs = Input(shape=(None,))
embedding = Embedding(vocab_size, latent_dim)
embedded_enc_inputs = embedding(encoder_inputs)
encoder = CuDNNLSTM(latent_dim, return_state=True)
_, state_h, state_c = encoder(embedded_enc_inputs)
# This is the encoded information we will pass over to the decoder
encoder_states = [state_h, state_c]
# Decoder
decoder_inputs = Input(shape=(None,))
embedded_dec_inputs = embedding(decoder_inputs)
decoder_lstm = CuDNNLSTM(latent_dim, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(embedded_dec_inputs,
initial_state=encoder_states)
decoder_dense = Dense(vocab_size, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
# The final model
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
model.summary()
With the default values I set above, we are getting around 3 million trainable parameters. This value is quite decent and should allow us to learn quite a few relationsips between sequences of words. You can tune the latent_dim to influence this number and change the capacity of the model.
Finally, let’s train it on your data.
# Run training
generator = DataGenerator()
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'],)
model.fit([encoder_input_data, decoder_input_data],
decoder_target_data,
epochs=100,
)
# Save model after training
model.save('/content/gdrive/My Drive/Projects/weights/mario_chatbot_v1.h5')
Chatbot phase 4: playing with our model
In order to sample things from our now trained model, we need to modify a bit the decoder. Don’t worry, we’re just creating a different interface for it, the trained weights will stay.
We need to get rid of the teacher forcing part now, and ‘release’ the state_inputs so that we can feed our own. We also want the decoder to just create one token at a time, so that we can feed in the token it just created as input in the next iteration.
# Define sampling models
encoder_model = Model(encoder_inputs, encoder_states)
decoder_state_input_h = Input(shape=(latent_dim,))
decoder_state_input_c = Input(shape=(latent_dim,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
embedded_dec_inputs = embedding(decoder_inputs)
decoder_outputs, state_h, state_c = decoder_lstm(
embedded_dec_inputs, initial_state=decoder_states_inputs)
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = Model(
[decoder_inputs] + decoder_states_inputs,
[decoder_outputs] + decoder_states)
Now lets define the function that will run this new decoder interface and create an output sequence given an input sequence. This function is the tool we have to ‘talk’ with out chatbot. As long as you use a sequence of words that are present in the word_to_ix dictionary, he will reply.
def decode_sequence(input_seq, t=None):
states_value = encoder_model.predict(input_seq)
target_seq = np.zeros((1, 1))
# Populate the first character of target sequence with the start character.
target_seq[0, 0] = word_to_ix['\t']
# Sampling loop for a batch of sequences
stop_condition = False
decoded_sentence = ''
iteration = 0
for _ in range(seq_length):
output_tokens, h, c = decoder_model.predict(
[target_seq] + states_value)
# Sample a token
sampled_token_index = np.argmax(output_tokens[0, -1, :])
sampled_word = ix_to_word[sampled_token_index]
decoded_sentence += " " + sampled_word
# Update the target sequence
target_seq = np.zeros((1, 1))
target_seq[0, 0] = sampled_token_index
# Update states
states_value = [h, c]
if sampled_word == '\r': break
return decoded_sentence
To create the input sequence, you need to turn a string into a vector of numbers. Let’s create a helper function for this.
def create_input_sequence(line):
input_seq = np.zeros((1, seq_length,), dtype=int)
splitted_line = re.findall('(?:[\p{L}]+)|\S', line, re.UNICODE)
print(splitted_line)
for i in range(seq_length):
if i < len(splitted_line):
input_seq[0][i] = word_to_ix[splitted_line[i]]
else:
input_seq[0][i] = word_to_ix['\v']
return input_seq
Finally, you can run the following to get an output from yout bot:
input = "hola"
print(decode_sequence(create_input_sequence(input)))
Thoughts
By running 100 epochs, we are clearly overfitting our data. Also notice that I did not use any validation nor regulation to the model. By overfitting it, we can check if we did things correctly or not. If you feed it an input sequence present in your data set, the model should reply with the corresponding target sequence. If this is not the case, something went wrong and you know you can start bug hunting. Once this is out of our way, we can start playing with regularization. Finding a good balance is crucial since the answers the model gives you can change drastically depending on it.
You can also play around with the probability distribution. For example, you can take a random choice with output_tokens[0, -1, :] probabilities, isntead of taking argmax. This will add some randomness to the model.
Thank you for following me to the end! Feel free to leave a comment.
Comments