
Deep Turing OCR: A Summary of my Bachelor’s Thesis
A short introduction to my final thesis project: performing OCR on hand-written Turing Machines with deep neural networks.
The Idea
I was attending a class on Models of Computation when the professor mentioned that it was very tedious to grade the final exams for this subject. One of the tasks (arguably the most important) is to write a Turing Machine by hand, capable of performing a specific operation (such as multiplication, division, exponentiation, etc). Each of these can have between 20 and 50 lines of state transition definitions, which look a bit like the following:

To evaluate the correctness of a Turing Machine, it is necessary to simulate it on a computer. The professor transcribed each Turing Machine manually into text, which could then be read by a simple simulator capable of checking if the machine is correct.
This immediately caught my attention, as I was currently hunting for an interesting thesis project. By using a neural network, it would be possible to convert image into text, which would greatly improve the speed at which one can grade Turing Machines. This project covered all the points I was looking for in a thesis project:
- Specific enough to be unique (I haven’t found anybody else working on Turing Machine OCR).
- Similar enough to other project (image to text, OCR) to be able to find supportive resources when needed.
- Challenging enough for me to learn from it.
- Related to my academic interests: Machine Learning / Neural Networks.
And so I ventured into building a system capable of inputting a scan of a Turing Machine, and outputting the text associated to that machine.
The code for this project can be found in this repository.
The Dataset
A scan of a Turing Machine may look like the following:
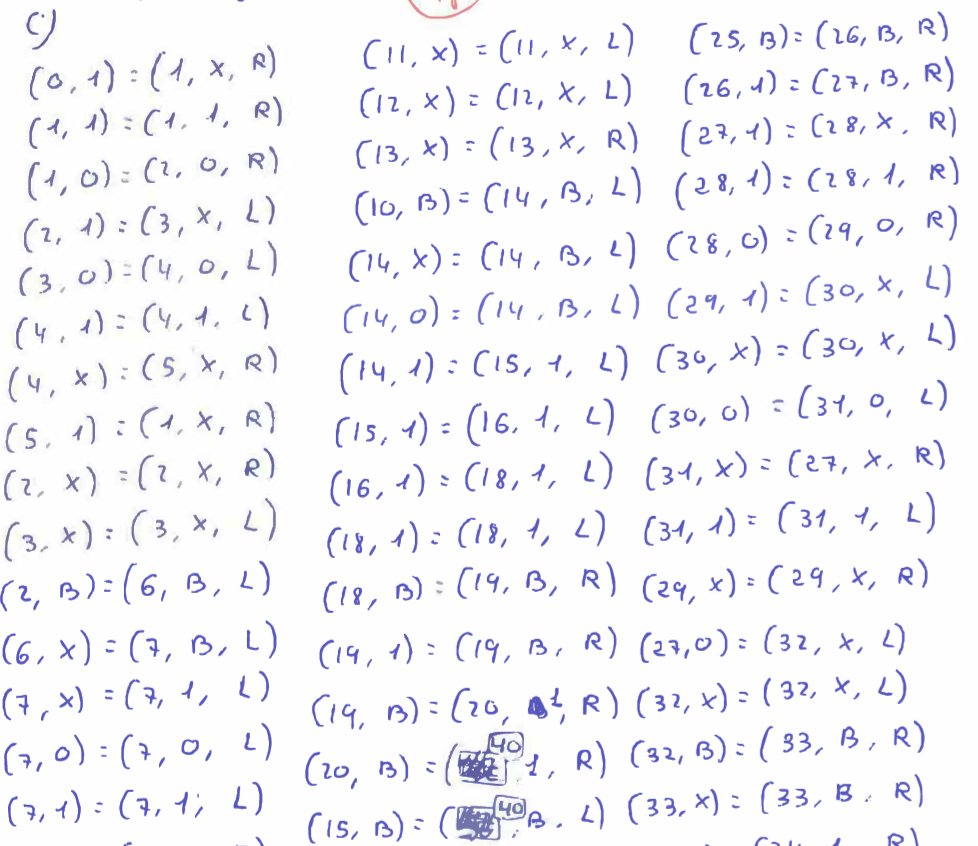 ]
]
In total, in collaboration with my supervisor, we have gathered more than 30 exams, and about 1500 Turing Machine definition lines. Each of these lines had to be manually labelled. The label for each line is a string, containing around 15 to 20 characters on average (this took a very, very long time 😥).
This is what later will be used to train the OCR model.
The Model
To be able to go from scan to text, there are two steps to overcome. First, localization, which is finding the areas where the transition definitions can be found. Then, on each of those, OCR has to be performed to extract the text. Integrating both into a seamless, end-to-end system would of course be ideal, but such a challenge is out of the range of an undergraduate thesis program. I decided to perform localization using the open source tool Tesseract. It is mainly an OCR tool, but can also be used to predict bounding boxes around regions of interest. I created a simple script that uses Tesseract to spit out the coordinates of the regions of interest of any given Turing scan.
The model that I built performs character recognition on the individual, cropped lines. The structure used is a CRNN, whose details are described in this paper. Basically, its a CNN followed by an RNN. First, the important features of the different characters in the image are extracted, and lined up as a sequence. Then, this sequence can be read by the RNN, which at the same time outputs character predictions. The whole thing is then trained using the CTC loss.
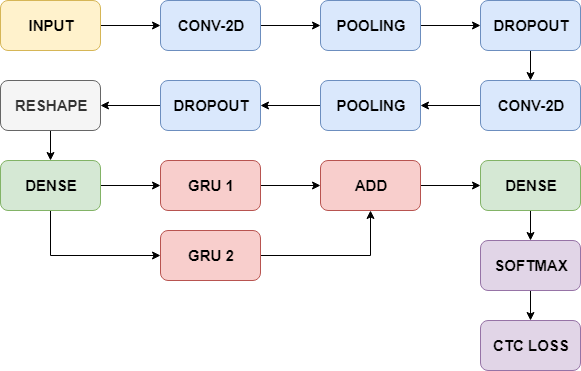 The network layers.
The network layers.
The Complete System
The system should be comfortable to use by people from any background. It should also be quick and assistive. Thus, I decided to wrap the scripts and the model into a backend, which offers an API to a web-based frontend. The user interacts with the model through an intuitive (yet visually rather mundane) interface, which looks like the following:

The user uploads a scan of a Turing Machine definition. Then they press the ‘Get Boxes’ button to obtain bounding boxes around the text. Those boxes can be resized and deleted on demand in case the predictions contained mistakes (Tesseract isn’t exactly flawless when it comes to messy handwritten Turing Machines…). Moving forward, the user can request the model’s OCR predictions. These will be displayed on the right-hand side. When hovering over a box or over the predicted text, the corresponding partner will also be highlighted. Mistakes made by the model can be easily amended by editing the text. Finally, the data can be saved both as a dataset for further training, or as part of a text file for posterior simulation.
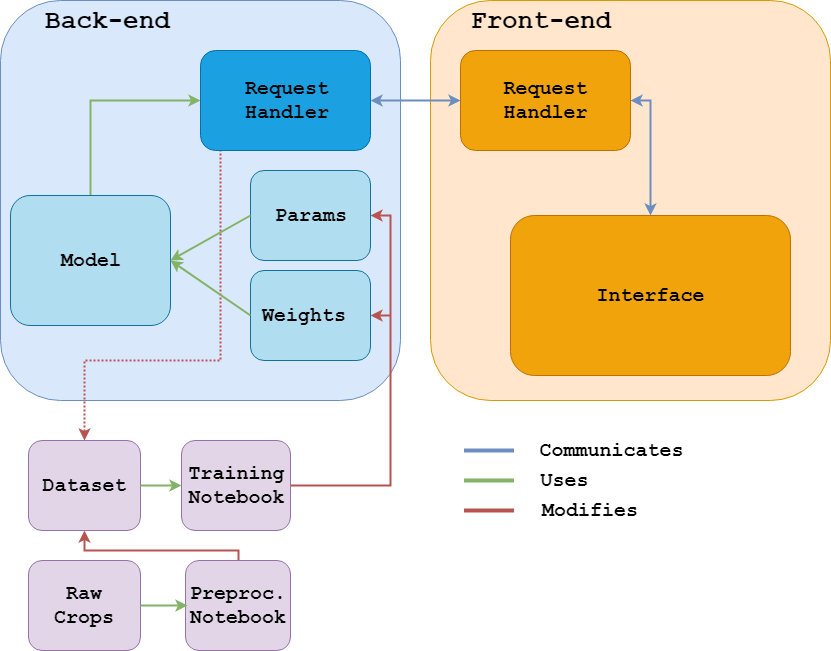 A summary diagram of the system, its modules and intercommunication.
A summary diagram of the system, its modules and intercommunication.
The Results
The metric used to track performance was edit distance, which is the number of edits necessary to go from the predicted string to the target string. After training, the average edit distance was 1.2. This means that although some predictions are flawless, others have one or two mistakes. Considering that that the ambiguity of some numbers and symbols is high for some types of handwriting, it’s quite an acceptable result. I am currently working on improving the model and dataset to drive this number down even further. Keep an eye on future posts!
Final Thoughts
It was a very valuable experience and I am very happy to have been able to work on this project. I leaned not only to build and train a rather complex network, but also to embed it into an integrated system. The fact that the end result is of practical use, even if just for a very small niche of people, makes it that much more satisfying. I faced uncountable bugs and errors, which took me an uncountable number of hours to hunt down and fix. I attribute this to poor debugging techniques and poor code structure. This experience has hopefully taught me to be more careful and organized, as well as be more thorough with my debugging.
Comments